
RAG란
LLM 관련 글이나 LangChain, OpenAI Assistants 문서 등에서 'RAG'란 용어를 자주 접할 수 있습니다. RAG(Retrieval-Augmented Generation)는 한국어로 '검색 증강 생성'이라고 번역합니다만, 무슨 말인지 이해하기 어렵게 느껴지네요.
보다 쉽게 이해하기 위해 RAG를 사용하는 대표적인 LLM 서비스인 질문-답변(Q&A) 챗봇을 예로 들 수 있습니다.
LLM은 자체적으로 광범위한 주제에 대해 추론할 수 있지만, 이러한 결과는 모델 생성에 사용된 특정 시점까지의 공개 데이터로 제한됩니다. 예를 들어, 2018년까지의 데이터로 학습된 모델은 그 이후 발생한 이벤트나 정보, 비공개 데이터에 대해서는 알지 못합니다.
모르는 걸로 그치지 않고 잘못된 대답을 만들어내는 경우가 있으며, 이런 오류를 '환각' 또는 '할루시네이션(Hallucination)'이라고 합니다.
이러한 문제를 해결하기 위해 필요한 정보를 프롬프트에 삽입하는 방식을 RAG라고 합니다.
RAG 아키텍처
RAG 아키텍처는 주로 두 가지 주요 구성 요소로 이루어져 있습니다.
인덱싱: 데이터를 소스에서 수집하고 인덱싱하기 위한 파이프라인입니다. 이 과정은 대개 오프라인에서 이루어집니다.
검색 및 생성: 사용자 쿼리를 런타임에 가져와 인덱스에서 관련 데이터를 검색한 후 이를 모델에 전달하는 실제 RAG 체인입니다.
인덱싱과 검색/생성을 구분하는 가장 중요한 이유는 데이터의 크기 때문입니다.
예를 들어, 회사 서비스에 관한 100페이지 분량의 문서가 있다고 가정해봅시다. 사용자의 질문과 100페이지 전체 내용을 프롬프트로 LLM에 전달한다면, 프롬프트 자체가 매우 커져 LLM으로부터 부정확한 답변을 받을 확률이 높아집니다.
또한, 자체 LLM이 아닌 OpenAI와 같은 서비스를 사용한다면 비용이 증가합니다.
토큰 개수 = 비용
이제 인덱싱과 검색 및 생성에 대해 좀 더 자세히 살펴보겠습니다.
인덱싱
이 단계에서는 문서를 청크, 즉 작은 단위로 분리합니다. 그 후에, 텍스트를 그대로 저장하는 대신 텍스트 임베딩 모델을 사용하여 텍스트를 벡터 값으로 변환합니다. 벡터로 변환된 값은 벡터 데이터베이스에 저장되며, 이는 이후 단계에서 유사도 검색(Similarity Search)에 사용됩니다.
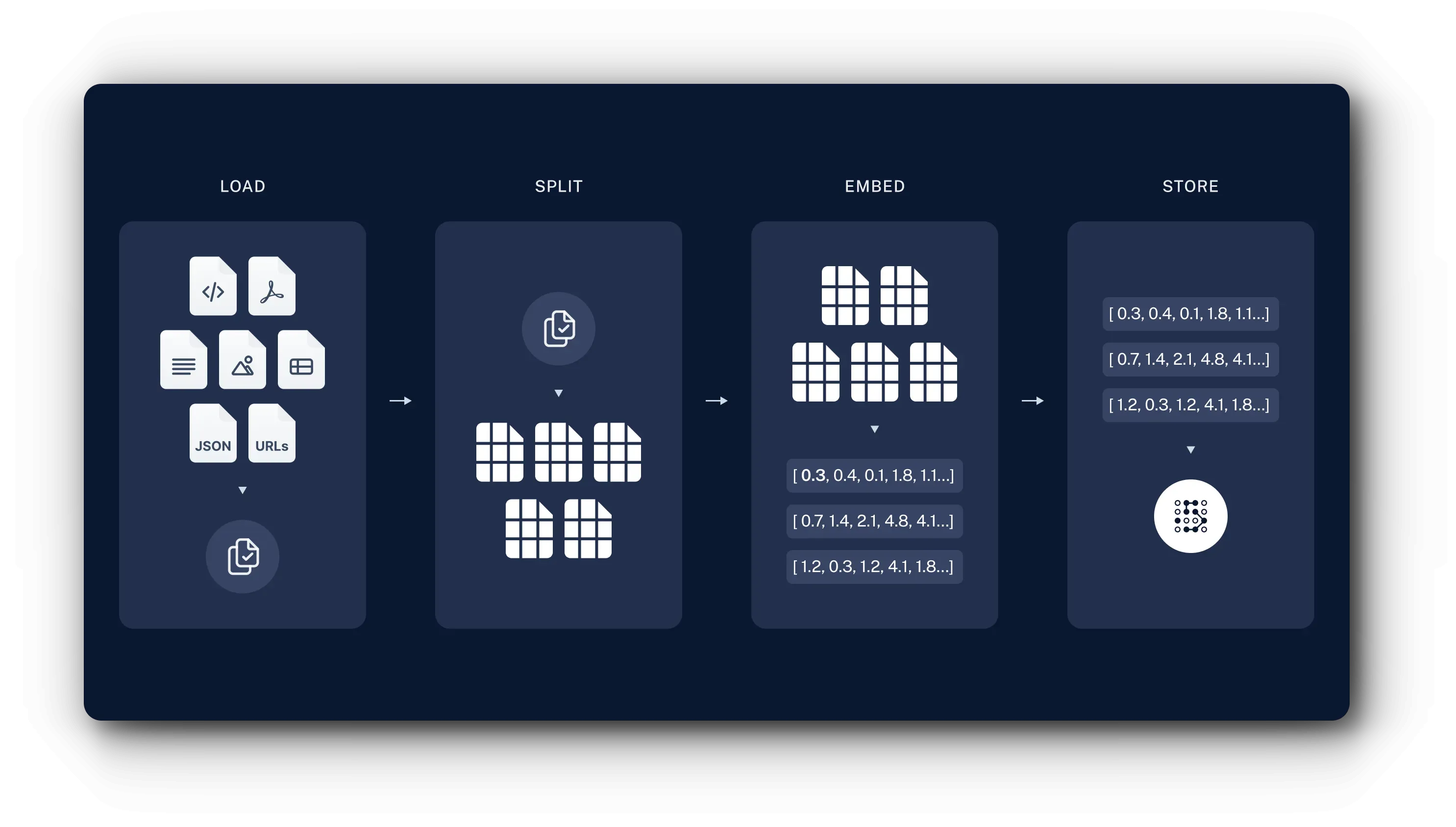
LangChain을 사용한 인덱싱 과정은 아래와 같습니다.
- Load : 먼저 데이터를 로드해야 합니다. 이는 DocumentLoaders 를 사용합니다.
- Split : 텍스트 분할기는 큰 문서를 더 작은 청크로 나눕니다. 이는 데이터를 인덱싱하고 모델에 전달하는 데 유용합니다. 큰 청크는 검색하기 어렵고 모델의 유한 컨텍스트 창에 맞지 않기 때문입니다.
- Store : 분할된 데이터를 나중에 검색할 수 있도록 저장하고 인덱싱할 위치가 필요합니다. 이는 VectorStore 및 Embeddings 모델을 사용하여 수행됩니다.
이 과정을 통해 문서가 청크로 분리되어 저장됩니다. 이렇게 저장된 데이터는 다음 검색 및 생성 단계에서 사용됩니다.
검색 및 생성
- 검색 : 사용자 입력이 주어지면 Retriever 를 사용하여 저장된 청크에서 유사도 검색을 합니다.
- 생성 : ChatModel / LLM은 질문과 검색된 데이터가 포함된 프롬프트를 사용하여 답변을 생성합니다.
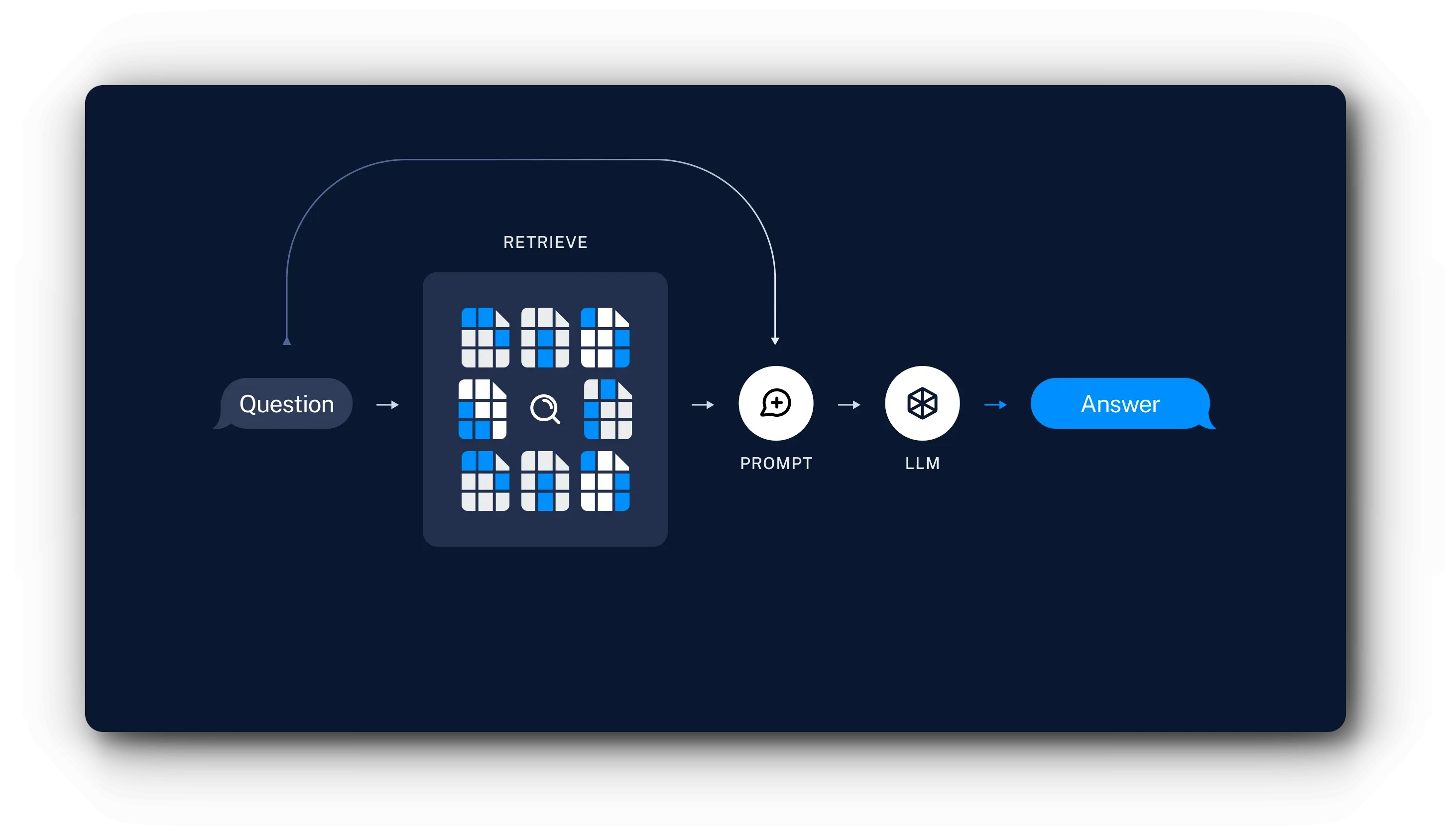
위와같이, LLM의 환각을 방지하고 적은 토큰으로 보다 정확한 응답을 생성하는 것이 RAG 아키텍처의 목표입니다.
Chains
LangChain은 이러한 단계를 쉽게 사용할 수 있도록 Retriever 및 Document Chain을 제공합니다. 이 섹션에서는 실제 체인 사용법이 아닌 LangChain에서 구현된 Document Chain이 어떻게 작동하는지에 대해 설명합니다.
LangChain은 최근 0.1.0 버전을 런칭하면서 이전에 사용하던 Chain들을 Legacy Chains로 분류했습니다. Document Chain도 이에 포함됩니다.
https://python.langchain.com/docs/modules/chains/#legacy-chains
위 페이지에 따르면, 0.1.0에서 제거된 레거시 체인은 0.2.0 버전에서 재작성되어 돌아올 예정입니다.
Stuff
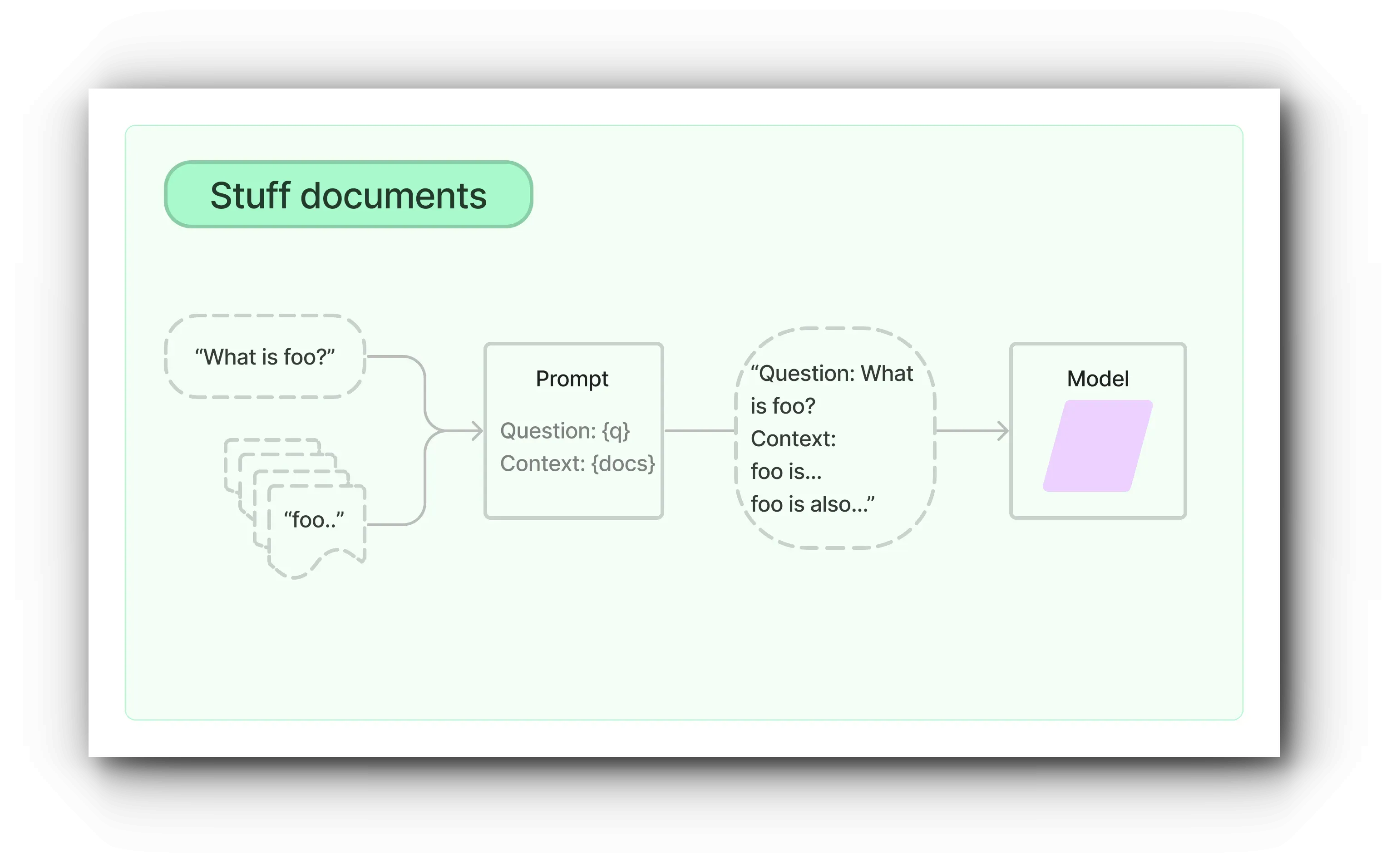
Stuff Documents chain은 앞서 설명된 과정 중 가장 기본적인 체인입니다. 이 체인은 인덱싱된 문서 목록에서 유사도 검색을 수행하여 결과를 얻고, 이를 바탕으로 문서 청크를 가져와 프롬프트를 생성합니다.
Refine
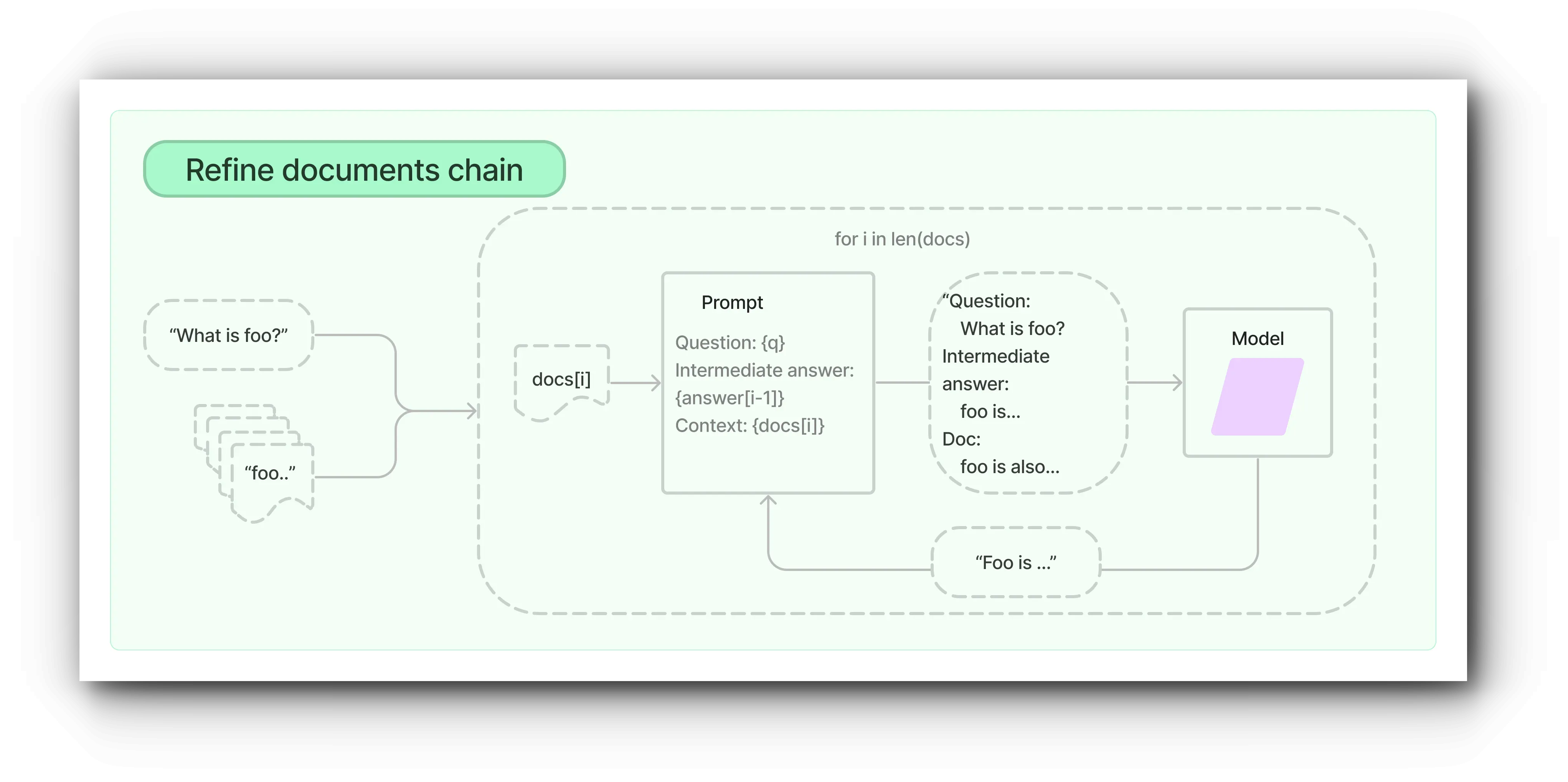
Refine document chain은 입력된 문서를 반복적으로 처리하고, 이 과정에서 답변을 지속적으로 업데이트하여 응답을 구성합니다. 이 체인은 각 문서에 대해 문서가 아닌 모든 입력, 현재 문서, 그리고 가장 최신의 중간 답변을 LLM 체인으로 전달하여 새로운 답변을 얻습니다.
예를 들어, 10개의 관련 문서가 있다면, 체인은 첫 번째 문서에 대한 응답을 받고, 그 응답을 바탕으로 다음 프롬프트를 생성합니다. 이러한 과정을 10개의 문서에 대해 반복하여 최종 결과를 반환합니다.
이 방식의 장점은 더 많은 문서를 분석할 수 있다는 것입니다. 하지만 단점으로는 LLM 호출 횟수가 많아지고, 병렬 처리가 아니기 때문에 결과 생성에 시간이 더 소요됩니다.
MapReduce
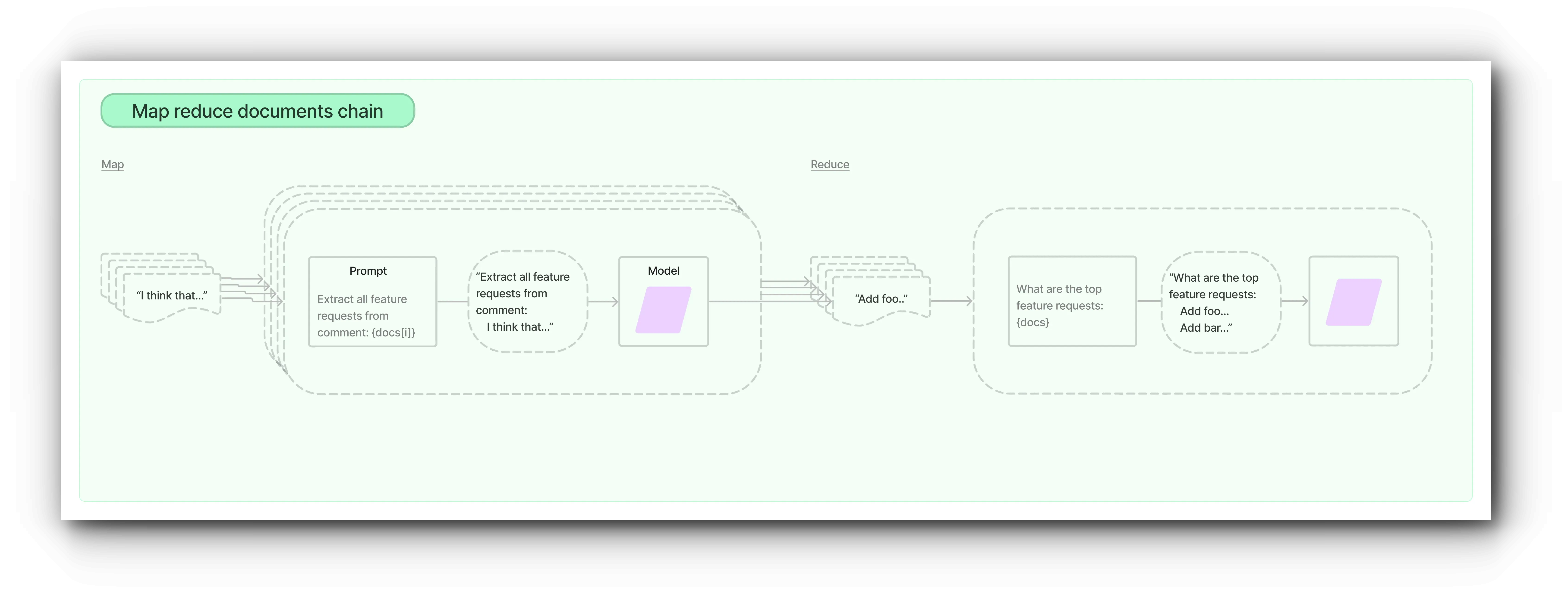
맵 축소 문서 체인은 먼저 각 문서에 LLM 체인을 개별적으로 적용하여(맵 단계) 체인 출력을 새 문서로 취급합니다.
그런 다음 모든 새 문서를 별도의 문서 결합 체인으로 전달하여 단일 출력을 얻습니다(축소 단계). 선택적으로 매핑된 문서를 먼저 압축하거나 축소하여 문서 결합 체인에 맞는지 확인할 수 있습니다(종종 LLM으로 전달됨). 이 압축 단계는 필요한 경우 재귀적으로 수행됩니다.
MapRerank
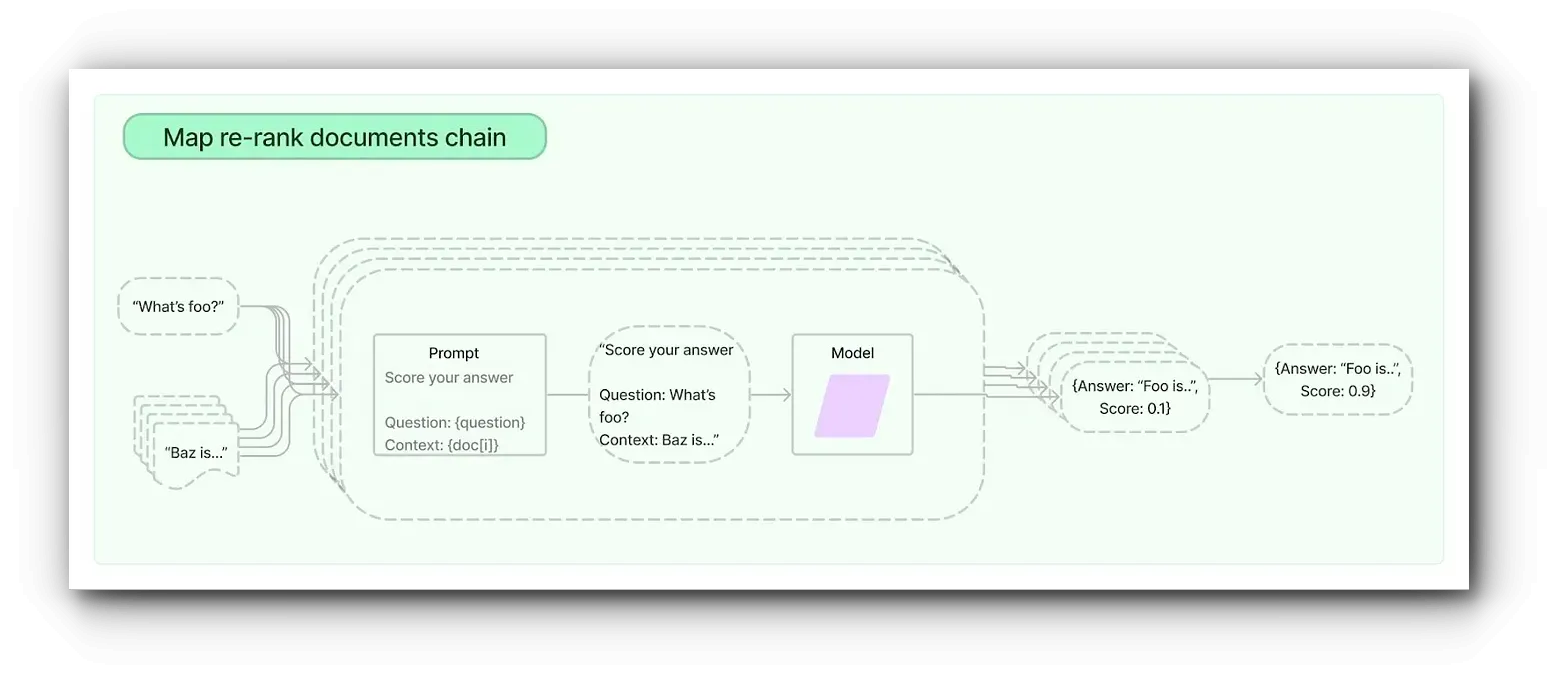
문서에 대한 별도의 프롬프트를 생성하여 병렬로 동시에 LLM에 전달합니다. 이 과정에서 결과에 대한 점수를 포함해 결과를 반환합니다. 이를 통해 모든 응답 중에서 점수가 높은, 즉 신뢰도가 높은 결과를 선택할 수 있습니다.
이 방법은 문서가 많을 때 유용하며, Refine 및 Reduce 메서드처럼 답변을 결합하지 않고 단일 문서를 기반으로 답변을 생성하려는 경우에 적합합니다.
마치며
글 작성 중 LangChain의 0.1.0 업데이트로 Chain 부분에 많은 변화가 생겼습니다. 비단 LangChain뿐만 아니라 AI 기술이 전반적으로 빠르게 발전하고 있어 배우는 입장에서는 어려울 수 있지만, 이러한 발전이 흥미로운 부분이기도 합니다.
References
- https://netraneupane.medium.com/retrieval-augmented-generation-rag-26c924ad8181
- https://python.langchain.com/docs/use_cases/question_answering/
- https://js.langchain.com/docs/modules/chains/document
- https://js.langchain.com/docs/modules/chains/document/stuff